
ML Training Objectives vs Business Objectives
ML Model Training Objective
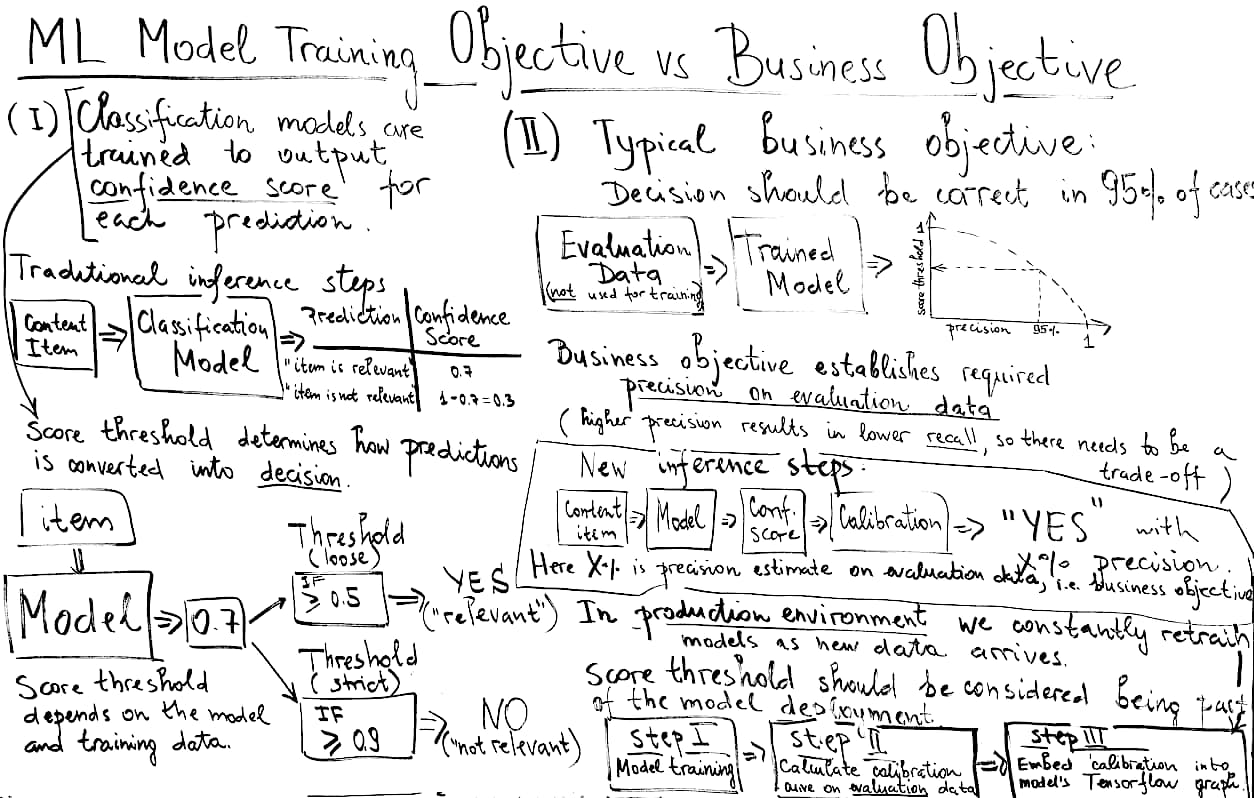
Consider classification models in machine learning. Such models are trained to output confidence scores for each prediction.
In our system the documents (Evi cards) are fed into a classification model which outputs such a confidence score. This confidence score, a number between 0 and 1, is used to decide whether the item is relevant or not. Specifically, we need to specify a score threshold which is then used to determine how predictions are converted into decisions: predictions with confidence score higher than score threshold are considered relevant. Score threshold is picked based on the model performance on evaluation data (i.e. representative data which was not used during training).
In a typical scenario we train and release new models twice a week as we collect more training data. Evaluation data is normally kept unchanged for much longer to allow assessing relative performance of new models.
It is important to realize that the score threshold depends on the model and training data and thus is potentially different for each model release.
Business Objective
Let’s get back to the model performance as perceived by the user, we call this business objective to differentiate from model training objective.
A typical business objective reads like: decisions should be correct in 95% of cases. Here “cases” refers to model performance in deployment, not in training, or at least on evaluation data which was not seen by the model during training.
To allow automation, let’s assume the business objective establishes required precision on evaluation data (as a side note: higher precision results in lower recall, so there needs to be a trade-off).
Having a model in production which outputs just the confidence score is inconvenient. This is because confidence score itself can not be interpreted as performance on evaluation data.
Augmenting ML Models to Output Business Objective
What if we make the model output not the confidence score, but instead a number which could be directly interpreted in a model-independent way?
To achieve that we need to embed a calibration curve into the model itself.
- Model training (this step is unchanged)
- Run the model on evaluation data to calculate calibration curve
- Embed calibration into models’s Tensorflow graph
As a result of this our classification model outputs model-independent estimates for each prediction.
For example, let’s assume the model outputs the decision “YES” with an estimate 97%. This estimate is directly interpretable. It is not a confidence score which requires a score threshold to make a decision. Instead we can compare this 97% value with our business objective (which in our example is 95%).
Model-independent confidence estimates simplify other things as well, e.g. they are comparable between different versions of the models in continuous deployment scenarios.