
Oct 15, 2023
·
5 min read
Simplifying our Machine Learning Ops with BigQuery ML
Training, evaluating and using ML models straight on logs directly from SQL
By:
Liudmila
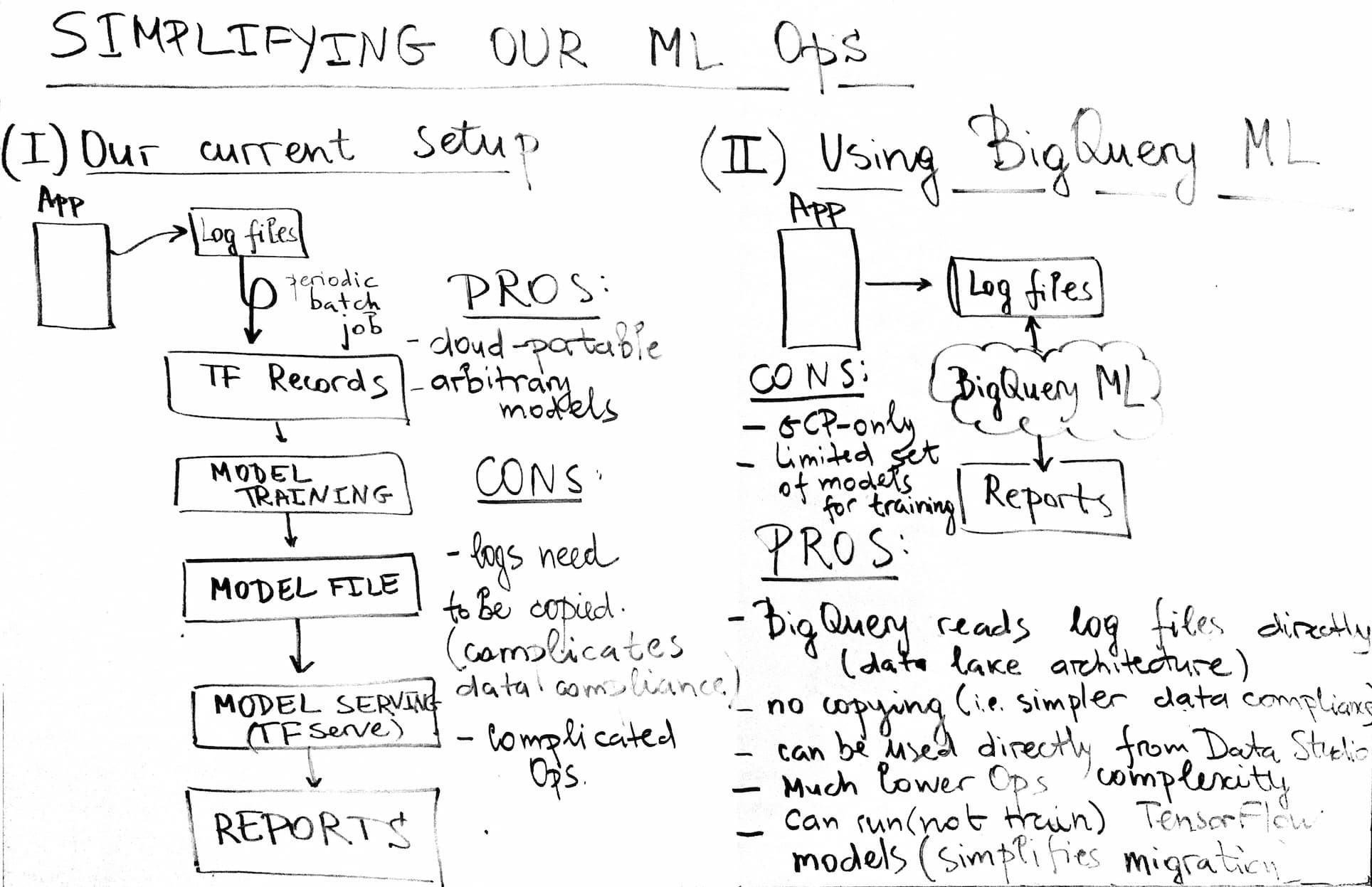
Traditional Architecture of Machine Learning Deployment
Currently Data from the app goes to log files which feed TF Records via periodic bath jobs. Then data feeds model training which … into a model file. Model serving (TF Serve) … reports.
Pros:
- Cloud-portable
- Arbitrary models
Cons:
- Logs need to be copied (this complicates data compliance)
- Complicated operations
Leveraging BigQuery ML
With BigQuerydata from the app is written to log files, this part stays the same. Unlike traditional approach BigQuery ML can read log files directly, no copies or additional pipelines are required.
This technical solution has a lot of benefits:
- BigQuery reads log files directly (data lake architecture)
- No need to copy data which means simpler data compliance (logs are not leaked into lots of other places, so they are easy to delete, etc)
- Models created by BigQuery ML can be used directly from Data Studio, i.e. we get much lower operations complexity
- BigQuery ML can run (but not train) TensorFlow models. This simplifies migration as we can import our legacy models into BigQuery ML and run them side by side with new models for evaluation prior to big switch.
As usual, there are some limitations:
- this is a CGP-only solution
- BigQuery ML supports a limited set of models for training (but there is support for AutoML!)
- At the moment there is no emulator for dev environment, i.e. we’ll have to run CI/CD pipeline on real BigQuery (we will need to add throttling to limit the usage bill).
Update:
1. We’ve just migrated one of our ML pipelines from Python (TensorFlow, Keras) to BigQuery
ML.
2. Engineering favourite: as part of that we deleted quite some Python, YAML and other
“glue” code!