
Serverless Recommendations System Architecture (Part 1)
Recommendation systems are typically considered to be too complex to run serverless (unless entire stack runs on the client side). There is one approach though that lets you store recommendations embeddings in a regular serverless database (for Evi App we use FireStore) and retrieve nominations using a single sorted index.
Embeddings
First, let’s recall how embeddings based recommendation systems work.
This post assumes you’re familiar with the concept of embedding from machine learning. As a quick summary embedding is a N-dimensional vector corresponding to input entity (e.g. a document or a query). There is great Machine Learning Crash Course from Google, they explain embeddings here .
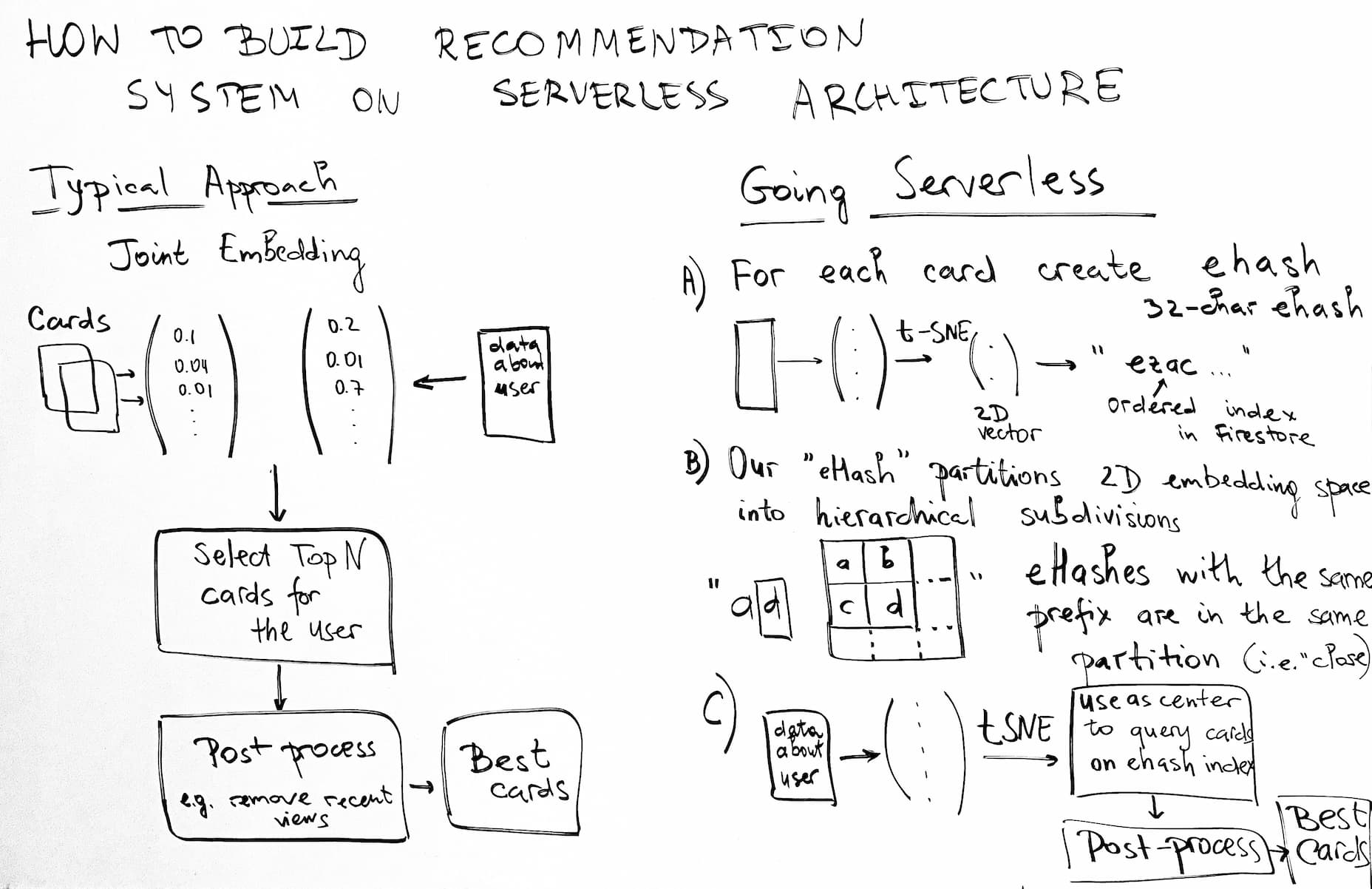
Traditional Approach
In our case all available information about each content card (document) is mapped into vectors in the embedding space (these are usually called document vectors). Similarly all the data about the user is mapped into a vector in the same embedding space (query vector).
Query vector is then compared to document vectors and top N closest ones are retrieved.
Resulting N documents are sourced to the user after post processing which includes removal of recently viewed cards and some other filters.
At this point we are ready to feed the best cards to the user!
Retrieval is Hard
- Embedding space is typically high dimensional (e.g. 1,024-dimensional)
- FireStore does not support multiple range queries
- Even with SQL or NoSQL DBs which do support multiple sorted indexes performance would likely suffer due to huge number of dimensions
- We need to retrieve documents based on distance which is inefficient to do with range queries.
Going Serverless
So… What do we do?
In short: we calculate a special string (which we call “eHash” – embedding hash) for each document and store them in FireStore. These eHashes are created in such a way that close embeddings will have the same prefix. We then use a single range query in FireStore to retrieve the right documents. Magic!
In practice, eHash is a 32-char string which partitions embedding space similar to k-d tree.
Another trick is to use dimensionality reduction before computing eHash. We found that t-SNE works great.
There are more details to share, stay tunned.
Meanwhile, we got our eHashes stored in FireStore and we know how to query them. Off you go! Best cards are on the user’s screen!
Update: Part II is ready.