
Serverless Recommendations System Architecture (Part 2)
You might want to check Part I of the series.
As you may have noticed for our Evi App we like serverless approaches. Recommendation systems are typically considered to be too complex to run serverless, but as we discussed in part I there is way to run them serveless.
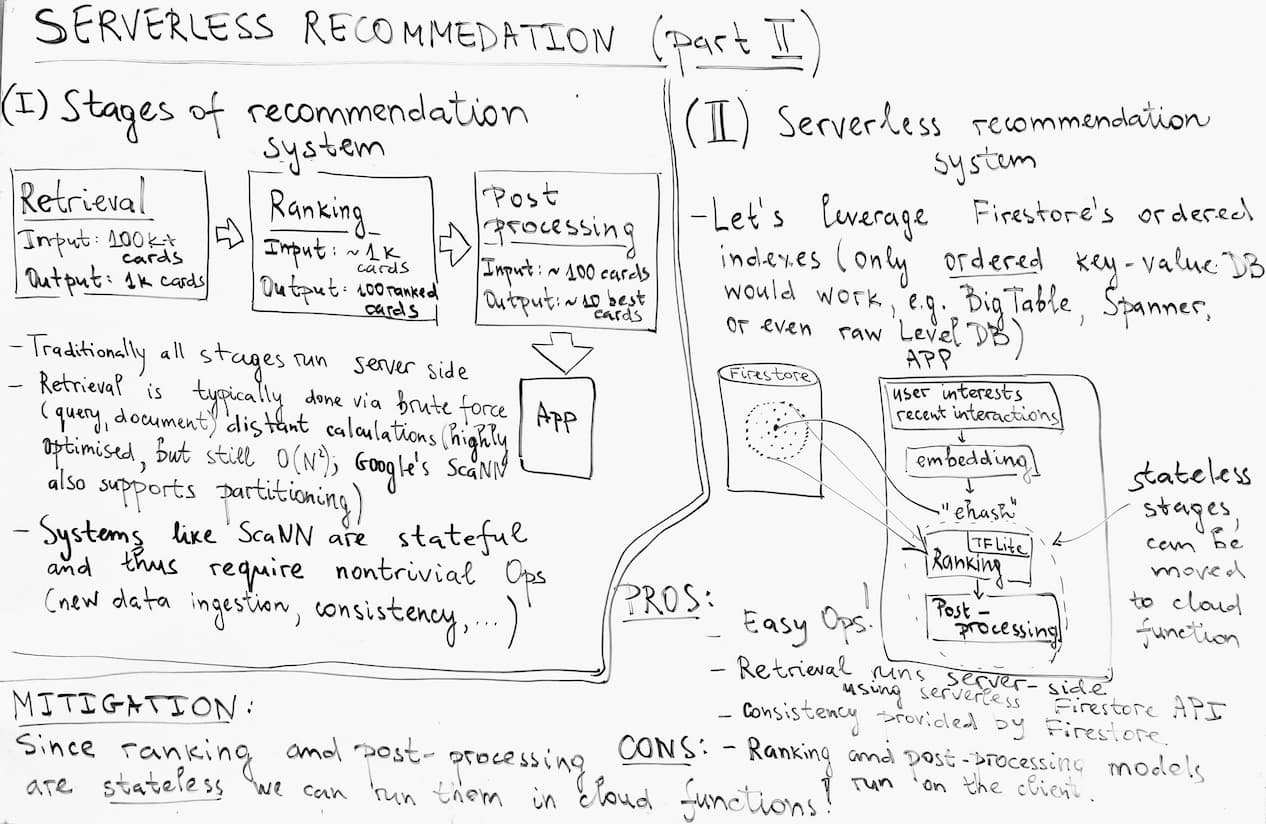
Stages of Recommendation System
- Retrieval, where out of 100,000+ available cards (documents) and we need to nominate about 1,000.
- Ranking, where we take nominated cards, rank them using e.g. listwise ranking model and output about 100 ranked cards
- Post-processing, is the final step, it takes about 100 ranked cards as an input and needs to output 10 best cards which would be fed to the App. Post-processing deals with knowledge which was not available during training, eg. it removes cards which the user have just seen.
Traditionally all these stages run on the server side.
Retrieval is typically done via brute force (query, document) distance calculations (this stage is often highly optimized, but it is still fundamentally O(N²); some systems, e.g. Google’s ScaNN, mitigate this via partitioning).
Systems like ScaNN are stateful and thus require non trivial operations (new data ingestion, consistency, …)
Serverless!
With serverless recommendation system we use special sortable embedding hashes (see Part I) which allow us to efficeintly make nearest neighbour queries directly from FireStore, no server code required!
We embed all the data we have about user’s interests and their recent interactions and calculate ‘eHash’. Essentially retrieval stage is happening server-side, but using serverless Firestore API! Next two stages, ranking and post-processing, have to be either executed on the client or in a (stateless!) cloud function.
Enjoy serverless operations!